CodilityのOddOccurrencesInArrayをPythonで解いてみた
こんにちは😄えびならいふです。
久しぶりにプログラミングに関する話題で、またまたCodilityというプログラミングテストのようなもののLessonをPythonで解いてみた話。
今日はその中の最初のLesson 2 OddOccurrencesInArrayという問題を解いてみた。
OddOccurrencesInArray
いつも通り、まずはOddOccurrencesInArrayがどういう問題かの説明。
入力は配列Aのみで、配列中でペアにならないにならない数値を返すという問題。
例えば以下のような配列Aが与えられた場合、
A = [9, 3, 9, 3, 9, 7, 9]
A[0]とA[2]が9でペア、A[1]とA[3]が3でペア、A[4]とA[6]が9でペアになりペアにならないのはA[5]の7となる。
問題はシンプルですごく簡単。
解いてみる
こういうプログラミングテストで注意しないといけないのは入力となる配列や変数の範囲だが、今回は特に気にする必要はなさそう。
プログラミング時の仮定として、配列Aの長さは奇数、1つを除いて偶数個出てくるという条件があるため例外的な処理も必要ない。
解き方はいくつかあるかもしれないが、今回はPythonのcollectionsにあるCounterを使って解く。
Counterを使うと配列などの要素をカウントしてくれて、要素ごとの出現数をConuter型 (dict形式に近い)で出してくれる。
要素ごとに出現数がわかるため、偶数になっているものは無視して、奇数になっているものを取り出せば良い。
実際に書くとこんな感じになる↓
from collections import Counter def solution(A): # 各要素の数をカウント count = Counter(A) for k, v in count.items(): # 1つ以外はペアになるので、各要素を見ていって、割って余りが1になっていればそれを返す if v % 2 == 1: return k
終わりに
今回の実装でスコアはこんな感じになる。

もっといい解き方はありそうだけど、とりあえず100点にはなるので良し。
CodilityのCyclicRotationをPythonで解いてみた
こんにちは😄えびならいふです。
今回は前回に続きプログラミングに関する話題で、CodilityというプログラミングテストのようなもののLessonをPythonで解いてみた話。
今日はその中の最初のLesson 2 CyclicRotationという問題を解いてみた。
CyclicRotation
まずはCyclicRotationがどういう問題かの説明。
入力は配列Aと自然数Kの2つで、Aの中の要素をK回ローテーションしたときにどんな配列になるかを当てれば良い。
例えば、以下のようなAとKが入力として与えられた場合、
A = [3, 8, 9, 7, 6] K = 3
Aを1回ローテーションするとA=[6, 3, 8, 9, 7]となり、2回目はA=[7, 6, 3, 8, 9]、3回目はA=[9, 7, 6, 3, 8]となり、この例だと答えは[9, 7, 6, 3, 8]となる。
この問題は親切にヒントも与えられていて、
A = [0, 0, 0] K = 1
の場合は答えが[0, 0, 0]となり、
A = [1, 2, 3, 4] K = 4
の場合は答えが[1, 2, 3, 4]となると書かれている。
以上のように問題は非常にわかりやすくて単純明快なので次からは実際に解いてみる。
解いてみる
こういうプログラミングテストで注意しないといけないのは入力となる配列や変数の範囲。
配列の長さが0の時とかに処理に失敗してエラーが出るなんてこともあり得るので、最初に長さ0の場合の処理を書いておく。
if not A: return A
また、Aの要素が全部同じ場合はローテーションする必要がないのでこちらも書いてしまっておく*1。
if set(A) == 1: return A
配列Aの長さ分ローテーションすると元の配列に戻るため、実際には律儀にK回ローテーションする必要はなく、Kを配列Aの長さで割った余りの分だけローテーションすれば良いのでKを以下のようにしておく。
Kが0もしくは配列Aと同じ長さの場合はそのままAを返す。
len_A = len(A) K = K % len(A) if K == len_A or K == 0: return A
ここまでくればほぼ終わり。
for文で回して一つずつ動かしてもいけるかもしれないけど、配列の長さが大きくなると少し大変なので少しだけ工夫してみる。
といっても大した工夫ではなくて、単純にsliceを使う方法。
ローテーションと言っても、後ろの数字列を前に持っていってるに過ぎないので、配列をsliceで前後に分けてそれを入れ替えればOK。
n = len_A - K # 分割位置 # 前と後ろに分割 A_a = A[:n] A_b = A[n:] # 後ろの数字列の後ろに元々前にあったやつをくっつける A_b.extend(A_a) return A_b
終わりに
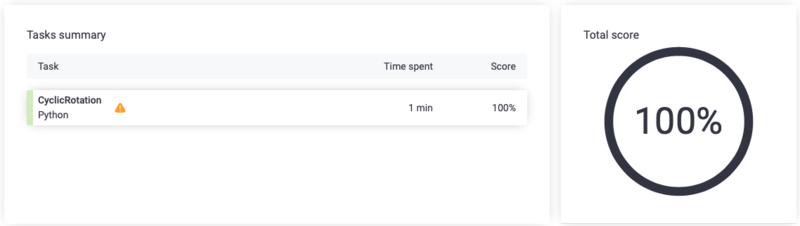
今回の実装でスコアはこんな感じになる。
*1:書かなくてもエラーになったりはしないが速度考えると書いておいた方が早い
CodilityのBinaryGapをPythonで解いてみた
こんにちは😄えびならいふです。
今日はプログラミングに関する話題で、CodilityというプログラミングテストのようなもののLessonをPythonで解いてみた。
Lesson自体はたくさんあるんだけど、今日はその中の最初のLesson 1 BinaryGapという問題を解いてみた。
ちなみにCodilityは英語で書かれているので英語が読めないとつらい。。
BinaryGap
BinaryGapは、ある10進数で書かれた自然数が与えられた際にそれを2進数に変換して、1と1の間にある0の数を数えてその最大値を返す問題。
例えば、10進数の32が与えられた場合、それを2進数に変換すると10000010001が得られる。
この時、1と1の間に挟まれている0は00000 (長さ5)と000 (長さ3)になり、長い方の長さである5を返すのが正解となる。
最初の問題だけあってそこまで難しくなさそうな問題ではある。
解いてみる
ということで早速解いてみる。 まずは10進数の数字を2進数に変換する。
binary_val = format(N, "b")
普通に解くとここからfor文で回して0の数を足し算していくような感じになるのだけど、ちょっと変わった解き方をしてみる。
1で挟まれた0を抜き出せば良いので、1の文字で文字列を分割する。
splited_val = binary_val .split("1")
このあとの処理を考えるためにいくつか実例を見てみる。
"10000010001".split("1") # ['', '00000', '000', ''] "1000001000".split("1") # ['', '00000', '000']
splitで分割されたリストの0番目は必ず空文字になる。
これは2進数にしたときに一番左が1になるためである。
一方でリストの一番最後は、1で終わる場合と0と終わる場合があり、1で終わると空文字になり、0で終わっている場合は分割されて得られた0の文字列となる。
こうなると少し処理がめんどくさそうに見えるが、問題自体が1と1の間にある0の長さを数えることなので、0で終わっている場合も無視することができる。
popを使ってリストの一番最後を削除する。
splited_val.pop()
ここまで来ると後はfor文を回して文字列の長さを見ていくだけで良い。
max_val = 0 for s in splited_val: n = len(s) if max_val < n: max_val = n return max_val
最初の空文字も少し気になるが、lenを取った時に0になるのでこちらも気にせず処理をしてしまっても問題ない。
スコアはこんな感じになる。

終わりに
今回はCodilityのBinaryGapを解いてみた。
初回とありそんなに難しい問題ではなかったが、少し特殊な解き方をしてみた。
Lesson 2からは難しい問題も増えてくるので少しずつ進めていきたい。
【技術】TransformersのAutoTokenizerにご注意を
海老名とかマンションの話をするとか言ってたそばから全然違う話を書くのもあれだけど、技術系の話を少ししたいと思う。 私はAIの中でも自然言語処理というところをメインにやっているので今日はその話。
BERTと呼ばれる自然言語処理の中でも強いとされてる手法があり、それを簡単に使えるPythonのライブラリにHuggingfaceのTransformersというのがある。その中のTokenizerのところでハマったところがあったのでメモ程度に残しておく。
【追記】2020年3月16日
Issueをあげてもらって解決したようです。
AutoTokenizer.from_pretrained doesn't work on newer models · Issue #24 · cl-tohoku/bert-japanese · GitHub
従来のモデルによるAutoTokenizerを使ったTokenize
BERTの事前学習モデルで割と有名なものに東北大の乾研究室が作っているものがあり、今回はそれに新しいモデルが追加されたというのをTwitterで見たので少し試してみようとしていた。Tokenizer自体は公式とかを参考にして次の感じで使う*1。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking') tok_res = tokenizer.tokenize("神奈川県民が選ぶ県内の“住みたい街ランキング”において、2020年は海老名が横浜に次ぐ第2位にランクイン。") print(tok_res)
['神奈川', '県民', 'が', '選ぶ', '県内', 'の', '“', '住み', 'たい', '街', 'ランキング', '”', 'において', '、', '2020', '年', 'は', '海老名', 'が', '横浜', 'に', '次ぐ', '第', '2', '位', 'に', 'ランク', 'イン', '。']
思ったより普通。悪くはなさそう。 上の例は単語分割を使った例だが、文字で分割したモデルも公開されていてそちらはこんな感じ。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-char-whole-word-masking') tok_res = tokenizer.tokenize("神奈川県民が選ぶ県内の“住みたい街ランキング”において、2020年は海老名が横浜に次ぐ第2位にランクイン。") print(tok_res)
['神', '奈', '川', '県', '民', 'が', '選', 'ぶ', '県', '内', 'の', '“', '住', 'み', 'た', 'い', '街', 'ラ', 'ン', 'キ', 'ン', 'グ', '”', 'に', 'お', 'い', 'て', '、', '2', '0', '2', '0', '年', 'は', '海', '老', '名', 'が', '横', '浜', 'に', '次', 'ぐ', '第', '2', '位', 'に', 'ラ', 'ン', 'ク', 'イ', 'ン', '。']
当たり前だが普通に文字単位に分割されていている。 ここまではこれまでも使われていたモデルで問題はない。 問題があったのは新しく追加されたモデルである。新しく4つほどモデルが追加されているのだが、これらはモデルを作るのに使ったWikipediaのデータが2020年のものが含まれている、UniDicという辞書が使われるようになっているなどの変更点があったりする。
新しく公開されたモデルによるAutoTokenizerを使ったTokenize
実際に例を見ていく。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-v2') tok_res = tokenizer.tokenize("神奈川県民が選ぶ県内の“住みたい街ランキング”において、2020年は海老名が横浜に次ぐ第2位にランクイン。") print(tok_res)
['神', '奈', '川', '県', '民', 'が', '選', 'ぶ', '県', '内', 'の', '“', '住', 'みたい', '街', 'ランキング', '”', 'に', '##お', '##い', '##て', '、', '2020', '年', 'は', '海', '老', '名', 'が', '横', '浜', 'に', '次', 'ぐ', '第', '2', '位', 'に', '##ラン', '##ク', '##イン', '。']
パッと見た感じではわかりづらいかもしれないが、「神奈川」、「横浜」が一文字ずつ分割されていておかしい。さらにおかしいのは文字分割の方。
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-char-v2') tok_res = tokenizer.tokenize("神奈川県民が選ぶ県内の“住みたい街ランキング”において、2020年は海老名が横浜に次ぐ第2位にランクイン。") print(tok_res)
['神', '奈', '川', '県', '民', 'が', '選', 'ぶ', '県', '内', 'の', '“', '住', '[UNK]', '街', '[UNK]', '”', '[UNK]', '、', '[UNK]', '年', 'は', '海', '老', '名', 'が', '横', '浜', 'に', '次', 'ぐ', '第', '2', '位', '[UNK]', '。']
単語の時と比べてこれは明らかにおかしい。上の単語の結果で1文字になってないところが全て[UNK]となっている。普通に文字に分割すれば良いはずなのにどうしてこんなことに、、、
解決方法
解決方法と言うほど大したことはない。AutoTokenizerではなく日本語用に用意されているだろうBertJapaneseTokenizerを使う。このあたり詳しい人たちは普通にこちらを使っているかもしれないが、これまでAutoTokenizerでも問題なかったので気にせずAutoTokenizerを使ってる人もいるかもしれない。 実際にBertJapaneseTokenizerを使うとこんな感じになる。
from transformers import BertJapaneseTokenizer tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-v2') tok_res = tokenizer.tokenize("神奈川県民が選ぶ県内の“住みたい街ランキング”において、2020年は海老名が横浜に次ぐ第2位にランクイン。") print(tok_res)
['神奈川', '県民', 'が', '選ぶ', '県', '内', 'の', '“', '住み', 'たい', '街', 'ランキング', '”', 'に', 'おい', 'て', '、', '2020', '年', 'は', '海老', '##名', 'が', '横浜', 'に', '次ぐ', '第', '2', '位', 'に', 'ランク', 'イン', '。']
先ほどのおかしい結果に比べると普通になっていることがわかる。 ヤバヤバだった文字分割も次の感じになる。
from transformers import BertJapaneseTokenizer tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-char-v2') tok_res = tokenizer.tokenize("神奈川県民が選ぶ県内の“住みたい街ランキング”において、2020年は海老名が横浜に次ぐ第2位にランクイン。") print(tok_res)
['神', '奈', '川', '県', '民', 'が', '選', 'ぶ', '県', '内', 'の', '“', '住', 'み', 'た', 'い', '街', 'ラ', 'ン', 'キ', 'ン', 'グ', '”', 'に', 'お', 'い', 'て', '、', '2', '0', '2', '0', '年', 'は', '海', '老', '名', 'が', '横', '浜', 'に', '次', 'ぐ', '第', '2', '位', 'に', 'ラ', 'ン', 'ク', 'イ', 'ン', '。']
文字単位で分割するだけでなんてことないはずなのに、ちゃんとした結果が出るだけでこんなに嬉しいとは笑。
おわりに
今回はTransformersのAutoTokenizerを使った場合に日本語の分割がおかしくなる問題を見てきた。東北大の以前から公開されているモデルではAutoTokenizerでも問題なく動いたが、新しいモデルではおかしくなってて気づかず使ってしまう人もいそうなので気をつけて欲しい。日本語の場合はAutoTokenizerよりBertJapaneseTokenizerを使うほうが良さそう!と言う話でした。
ではでは。
*1:例の文はセントガーデンのHPより